I recently took some time to explore Convex, and I'm writing down my thoughts and learnings in the hopes someone finds it useful, but mostly to solidify my own understanding.
Like I generally do with technical writing, I want to start by discussing the problems in traditional systems and how Convex thinks about solving them differently. This helps understand why it's been gaining adoption and makes the core product easier to grasp.
Feel free to skip to the good stuff (depending on what that is for you).
The Traditional Way(s)
All of this discussion boils down to how applications talk to their data. Every architectural pattern over the years has emerged as a way to solve specific pain points of the previous generation. I want to briefly touch upon each before we move on to understanding how Convex works.
The REST Era
Since the beginning of modern web development, we've had REST APIs. The pattern was straightforward: your frontend makes HTTP requests to specific endpoints, each endpoint corresponds to a server function that reads or writes data, and the server sends back a response.
Building a blog app, you'd have GET /api/posts that retrieves all posts, GET /api/post/123 for a specific post, and POST /api/create to add new ones. Each endpoint is a simple HTTP request-response cycle.
This model maps cleanly to how the web works. HTTP is request-response by nature. You ask for something, you get a response, the connection closes. Simple and stateless.
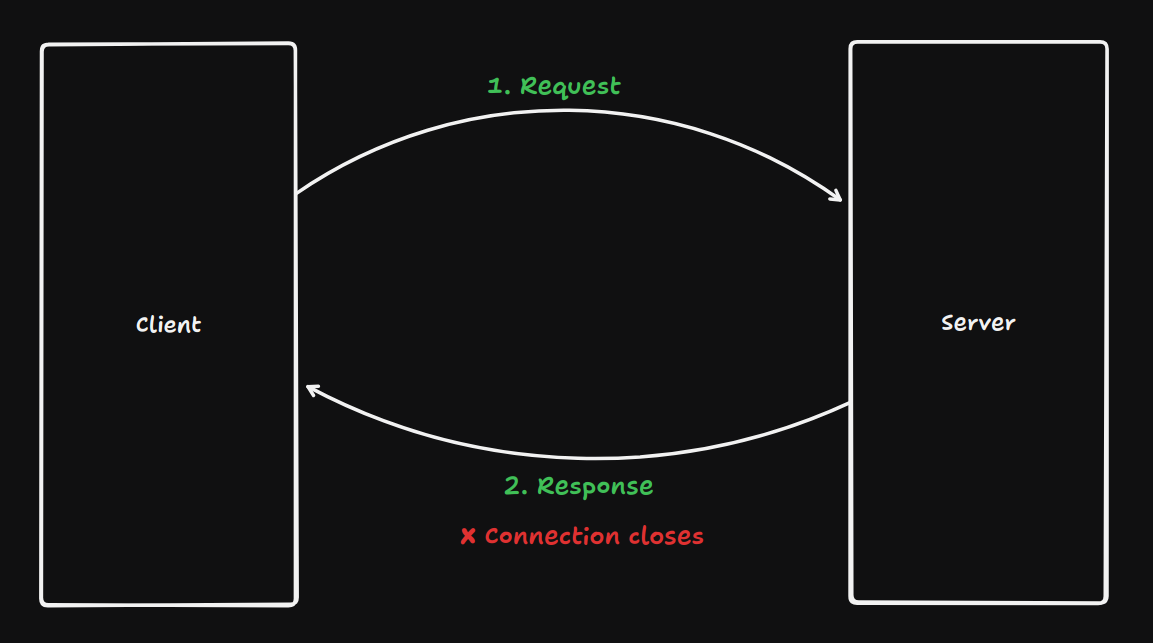
But complexities emerge as the application grows.
If you need a post plus its author, comments, and like count, you're either making multiple requests (under-fetching) or your endpoint returns everything including data the client doesn't need (over-fetching). Your mobile app needs data in a different shape than your web app. Do you create separate endpoints? Do you version your API? Each of these approaches create maintenance overhead.
However, the real problem here is: HTTP is fundamentally request-response. If you want the client to know when data changes, you need to build additional infrastructure – Polling, WebSockets, SSE. Polling wastes bandwidth, WebSockets require separate server setup, Server-sent events are one-way only. As you'd notice, each solution is bolted on top of REST, not integrated with it.
GraphQL
GraphQL emerged to solve the data fetching problem. Instead of hitting fixed endpoints that return predetermined shapes, the client declares exactly what data it needs through a query language. The server has a schema describing all possible data and a resolver system that fetches each piece.
This solved over-fetching and under-fetching quite elegantly. It also solved versioning – add new fields to your schema without breaking old queries.
But GraphQL introduced new complexities too. Each field in your query might trigger a separate database call. Without careful optimization, you end up with N+1 query problems. You're also writing a lot of code to wire up your schema to your database. Every non-trivial field needs a resolver function.
And real-time still remains an add-on. GraphQL has subscriptions, but they're a separate concept from queries. You write queries for initial data, then write separate subscription definitions for updates. The mental model still splits between "data fetching" and "data watching."
tRPC
As TypeScript adoption grew, tRPC was introduced, and it made a compelling case: what if your API was just TypeScript functions, and the client could call them with full type safety? No schema language, no codegen, just functions and types.
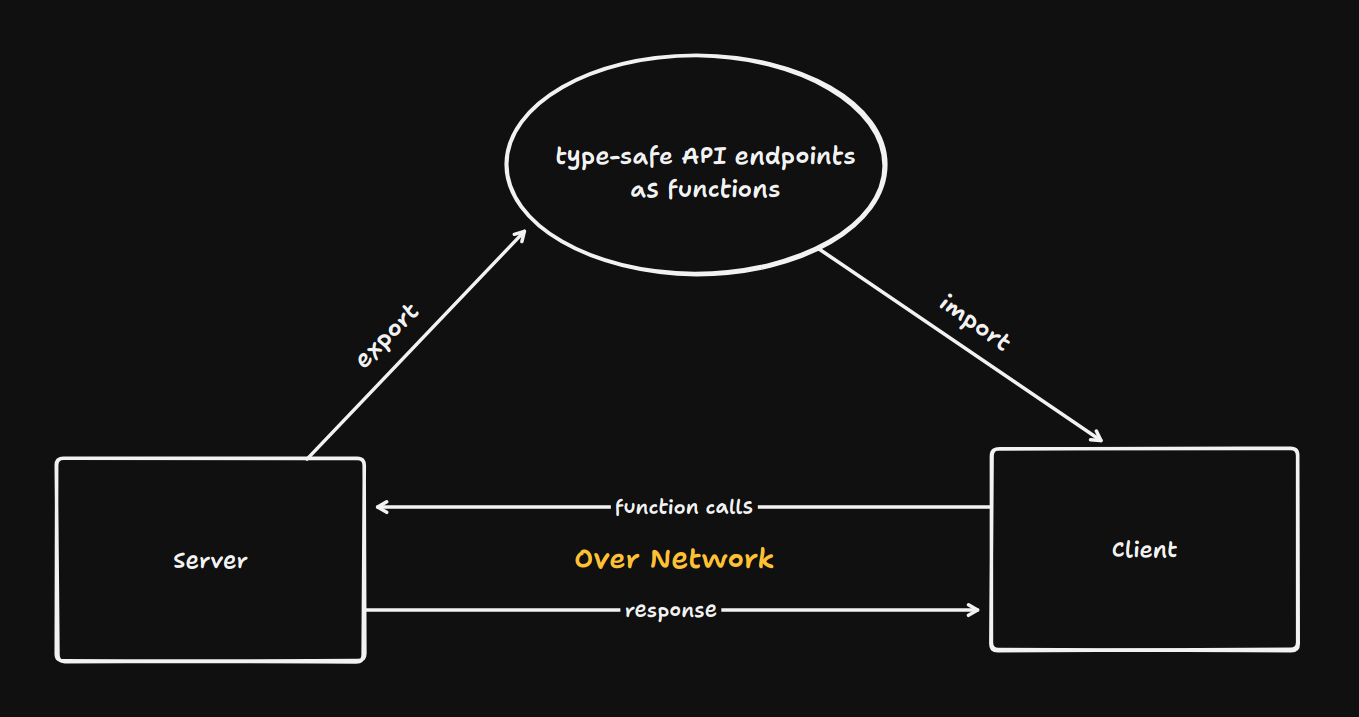
You refactor a backend function's return type, and TypeScript immediately shows you every frontend call that needs updating. I honestly love this so much. End-to-end type safety catches entire classes of bugs before runtime.
But tRPC didn't solve the real-time problem. It's still fundamentally request-response. For live updates, you're back to manually setting up WebSockets or other push/pull mechanisms.
The Fundamental Gap
Looking at this evolution, one would notice a pattern emerging. Each generation improved data fetching – making it more efficient, type-safe, flexible. But they all treated real-time updates as a separate concern, something you add on top.
This creates a split in how you think about data. Static data uses queries to fetch it. Live data needs separate subscriptions to watch it.
But if you think about it, most data isn't purely static or dynamic. Take the example of a post: A post's content rarely changes, but its like count changes frequently. Do you treat it as static or live? The answer is both, but existing tools make you choose or build complex hybrid systems.
This choosing leads to a deeper issue: these tools separate the mechanism of data access from the mechanism of data synchronization. You fetch data through one system (REST/GraphQL/tRPC) and subscribe to changes through another (WebSockets/Polling/SSE). This separation is the root of complexity in real-time applications.
How Convex Fills This Gap
Convex's insight seems to be that queries and subscriptions should be the same thing. When you query for data, you're simultaneously expressing interest in that data's future changes. There shouldn't be a separate subscription API – the query is the subscription.
This sounds simple, but it requires rethinking the entire stack. You can't just bolt this onto a traditional database. The database itself needs to understand queries as subscriptions, track which clients care about which data, and efficiently propagate changes.
Hence Convex is a separate backend platform, and not just a library.
How Convex Works
I initially understood Convex as "backend with WebSockets built in." That's partially true but undersells what's happening. Wiring up WebSockets still requires manually describing which parties to propagate updates to.
Convex figures this out automatically. This comes down to its core architecture: queries, mutations, and actions.
Queries: Pure Computations Over Data
A query in Convex is a server function that reads data from the database and returns a result. The critical constraint: queries are read-only. They cannot modify the database.
export const getAllPosts = query(async (ctx) => {
return await ctx.db.query("posts").order("desc", "_creationTime").collect();
});
This function receives a context object (ctx) which gives database access through ctx.db. Standard database stuff.
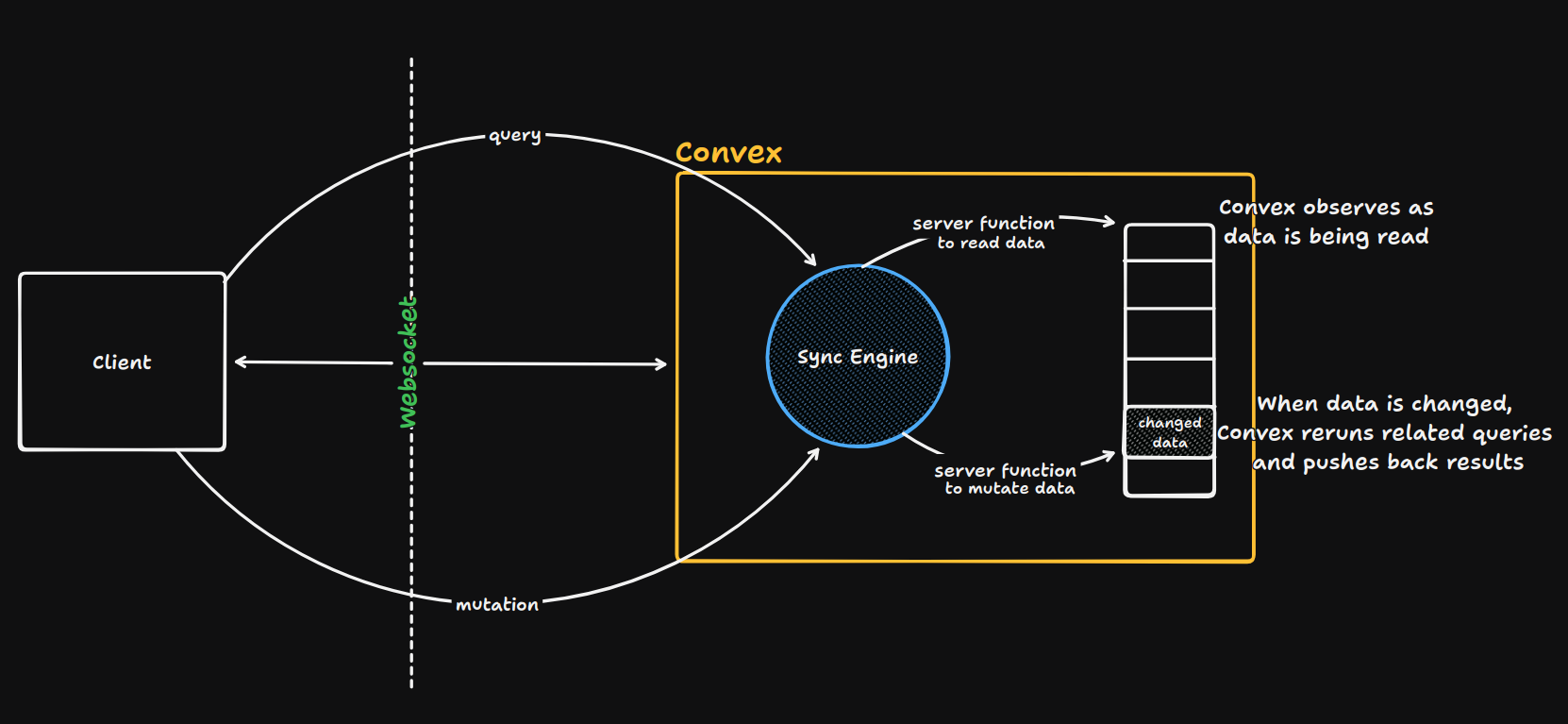
Here's what makes it special though: because Convex knows this function is read-only, it can observe exactly which database documents the query reads. Not just "it reads from the posts table" but specifically "it read document A, document B, document C." This observation happens automatically as your code runs.
This builds a dependency graph. The query result depends on these specific documents. When any of those documents change, Convex consults this graph, finds every query that depends on the changed document, reruns those queries with the new data, and pushes the updated results to clients over WebSockets.
The read-only constraint is what makes this observation safe. If queries could modify data, you'd face a chicken-and-egg problem. A query modifies data, invalidating other queries, which rerun and modify more data, invalidating more queries – creating potential infinite loops. Separating reads (queries) from writes (mutations) avoids this entire class of problems.
Mutations: State Transitions
Mutations are functions that change data. When you need to create, update, or delete data, you write a mutation.
export const likePost = mutation(async (ctx, { postId }) => {
const post = await ctx.db.get(postId);
await ctx.db.patch(postId, {
likeCount: post.likeCount + 1,
});
});
Mutations receive the same context object as queries, but they're allowed to modify the database through operations like ctx.db.insert(), ctx.db.patch(), and ctx.db.delete(). They can also read data (this mutation reads the current like count before incrementing it).
Everything inside a mutation runs as a transaction. Either all database operations succeed, or none do. This transactional guarantee extends beyond just database operations, to the entire mutation. All its logic, all its reads, all its writes execute in isolation from other mutations.
When a mutation completes successfully, Convex looks at what data was modified, checks the dependency graph to find all queries that depend on the modified data, invalidates those queries, automatically recomputes them, and pushes results to clients who had those queries active.
This separation of concerns is important. The mutation just says "change this data." It doesn't say "notify these clients" or "invalidate these caches." The mutation doesn't even know which queries are watching, or depend on the changed data. The reactive system handles propagation automatically based on the dependency graph that queries created.
Actions: Escape Hatches
Queries and mutations live entirely within Convex's transactional world. But real applications often need to interact with the outside world – calling external APIs, sending emails, processing payments – you get this gist.
Actions are for this. They're functions that can do anything, call external services, perform non-deterministic operations, take time to execute.
export const sendWelcomeEmail = action(async (ctx, { userId }) => {
const user = await ctx.runQuery(api.users.getUser, { userId });
await sendEmail(user.email, "Welcome to Waypoint!");
});
Actions can't directly access the database. Instead, they call queies and mutations using ctx.runQuery() and ctx.runMutation(). This enforces a clean boundary. The transactional world (queries and mutations) stays deterministic and replayable, while the non-transactional world (actions) is explicitly separate.
This separation matters because mutations need to be deterministic. Convex might replay them for consistency guarantees. If a mutation called an external API, replaying it would call that API multiple times, potentially charging your credit card twice or sending duplicate emails. By forcing external calls into actions, Convex ensures that mutations remain safe to replay.
Actions also don't participate in the reactive system. They're one-shot operations. You call an action, it does its thing, it returns.
The Reactive Query System
When you use a query in your React component, you're not just fetching data once. You're establishing a live connection between your UI and the server-side computation.
In my Waypoint app, I wrote:
const posts = useQuery(api.posts.getAllPosts);
Here's what happens when this line executes.
Your React component renders and the useQuery hook tells Convex "I need the result of the getAllPosts query function." On the Convex server, your query function executes. As it runs, Convex watches every database operation. When your code does ctx.db.query("posts"), Convex intercepts this and records the ID of every document your code touches.
To understand it more clearly: if your database has three posts with IDs "post1", "post2", and "post3", Convex builds a dependency record: "The result of getAllPosts depends on documents post1, post2, and post3."
The query completes and returns the array of posts. This result is cached on the server, tagged with its dependencies. The result sends to your client over a WebSocket connection. Your React component receives the data and renders.
The WebSocket stays open. Your client maintains an active subscription to this query's results. On the server, Convex maintains a mapping: "Client A is subscribed to the getAllPosts query, which depends on documents post1, post2, post3."
When someone clicks the like button on post2, the likePost mutation executes and modifies the like count in the post2 document. When the mutation completes, Convex checks what changed. The post2 document was modified. Convex checks its dependency graph: "Which queries depend on post2?" It finds getAllPosts in the list and marks the cached result as stale.
Convex immediately reruns the getAllPosts query function. Same function, but fresh execution. It reads from the database again, getting the updated post2 with its new like count. The query returns a new result – an array of posts with post2's updated like count.
Convex looks at which clients are subscribed to getAllPosts, finds your browser in the list, and sends the new result over the existing WebSocket connection. Your useQuery hook receives the update, React's state updates, and your component re-renders with the new data.
You wrote none of the coordination code. No WebSocket management, no invalidation logic, no broadcast lists. This is why I'd able to built Waypoint in 4 hours.
What I Learned
Building Waypoint took 4 hours. I didn't spend three of those hours on infrastructure setup. No configuring WebSocket servers. No setting up pub/sub. No writing cache invalidation logic.
I wrote queries and mutations and the reactive system handled everything else.
My initial mental model was wrong. I thought Convex was "a database with WebSockets built in." It's not really that. It's more accurate to say it's a reactive computation system that happens to store data. The database serves the reactive queries. The WebSockets deliver updated results. But the core mechanism is the automatic dependency tracking.
In my previous WebSocket setups, every feature meant thinking through: which clients need this update? How do I propagate it? What happens on reconnect? How do I keep state consistent across everyone?
Those questions don't exist with Convex. You just write functions that read data. The system observes what you read. When data changes, your functions rerun automatically. Results push to whoever's subscribed.
I'm still thinking through the implications of this model. There are tradeoffs I haven't fully explored yet. But for building something quickly where real-time is a requirement, not a nice-to-have, this approach worked better than anything I've used before.
The separation between queries, mutations, and actions feels really clean. Queries can't modify state, so the dependency tracking stays predictable. Mutations handle all writes transactionally. And Actions deal with the outside world. Each piece has one job.
I don't know if this is how we should be building all real-time applications going forward. But it's definitely worth understanding if you're building anything that needs live updates without the usual infrastructure overhead.
Built with 4 hours and coffee at a Capital One Cafe in downtown Manhattan.